

Pentru a înțelege cum poate fi influențată căutarea de către machine learning, este necesară o aprofundare a modelelor și algoritmilor utilizați de Google în momentul căutării și la afișarea rezultatelor.
În ceea ce privește conceptul de machine learning, există câțiva termeni generali care sunt esențiali a fi cunoscuți. În primul rând, este important de știut unde este machine learning utilizată, dar și care sunt principalele tipuri de învățare existente.
Prezentul articol explică felul în care machine learning impactează căutarea, modul de funcționare al unui motor de căutare, dar și modul în care machine learning poate fi recunoscută. Totodată, acesta prezintă algoritmii și modelele de machine learning.
Termeni referitori la machine learning
Mai jos, expunem câțiva termeni frecvent utilizați atunci când vorbim despre domeniul machine learning.
Algoritm: Un proces matematic executat pe date pentru a produce un rezultat. Există diferite tipuri de algoritmi pentru diferite probleme ale machine learning-ului.
Artificial Intelligence (AI): Inteligența artificială - un domeniu al informaticii axat pe dotarea calculatoarelor cu aptitudini sau abilități care reproduc sau sunt inspirate de inteligența umană.
Corpus: O colecție de texte scrise, organizată într-un anumit mod.
Entitate: Un lucru sau un concept care este unic, singular, bine definit și care poate fi distins. Culoarea roșu, spre exemplu, este o entitate. În acest sens, aceasta este unică și singulară în sensul că nimic altceva nu este exact ca ea, este bine definită și se poate distinge, fiind ușor de deosebit de oricare altă culoare.
Machine Learning: Un domeniu al inteligenței artificiale, axat pe crearea de algoritmi, modele și sisteme care să îndeplinească sarcini și, în general, să se îmbunătățească pe sine în îndeplinirea sarcinilor respective fără a fi programate în mod explicit.
Model: Un model este adesea confundat cu un algoritm. Distincția poate fi, într-adevăr, neclară. În esență, diferența constă în faptul că, în timp ce un algoritm este pur și simplu o formulă care produce o valoare de ieșire, un model este reprezentarea a ceea ce a produs acel algoritm după ce a fost antrenat pentru o anumită sarcină.
Natural Language Processing (NLP): Un termen general care descrie domeniul de lucru în care se prelucrează informații bazate pe limbaj pentru a îndeplini o sarcină.
Neural Network: Un model de arhitectură care, inspirându-se din modul de funcționare al creierului, include un strat de intrare (în care intră semnalele - în cazul unui om, se poate considera că este semnalul trimis la creier atunci când acesta atinge un obiect), un număr de straturi ascunse (care oferă un număr de căi diferite prin care intrarea poate fi ajustată pentru a produce o ieșire) și stratul de ieșire. Semnalele intră, testează mai multe „căi" diferite pentru a produce stratul de ieșire și sunt programate să graviteze spre condiții de ieșire din ce în ce mai bune.
Care este diferența dintre inteligența artificială (AI) și machine learning?
Adesea, cuvintele inteligență artificială și învățare automată par a avea același înțeles. Ele sunt, totuși, diferite.
Inteligența artificială este domeniul în care mașinile imită inteligența, în timp ce machine learning este căutarea unor sisteme care pot învăța fără a fi programate în mod explicit pentru o anumită sarcină.
Diferența este ilustrată în imaginea de mai jos:
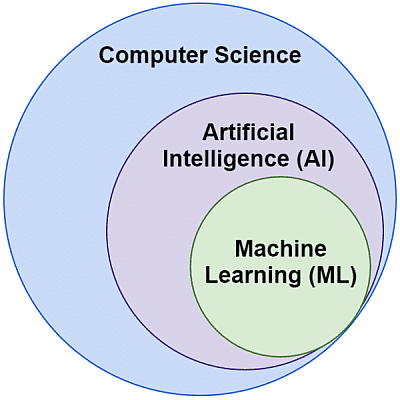
Sursa imagine: https://searchengineland.com/machine-learning-search-terms-concepts-algorithms-383913
Algoritmii de învățare automată ai Google
Toate motoarele de căutare importante utilizează învățarea automată într-unul sau mai multe moduri. Totodată, atât Microsoft, cât și rețelele de socializare precum Facebook (Meta AI), fac progrese semnificative în acest sens.
Google utilizează o multitudine de algoritmi de machine learning. Este literalmente imposibil ca cineva să cunoască toți acești algoritmi. În plus, mulți dintre ei sunt pur și simplu eroi necunoscuți ai căutării și nu este nevoie să fie explorați pe deplin, rolul lor principal fiind acela de a se asigura că alte sisteme funcționează la nivel optim.
Printre algoritmii de machine learning ai Google se numără:
- Google FLAN - care accelerează și face mai puțin costisitor din punct de vedere computațional transferul de învățare dintr-un domeniu în altul. De remarcat este faptul că în cazul învățării automate, un domeniu nu se referă la un site web, ci mai degrabă la sarcina sau la grupurile de sarcini pe care le îndeplinește, cum ar fi detectarea obiectelor în Computer Vision (CV).
- V-MoE - singura sarcină a acestui model este de a permite instruirea modelelor de viziune mari cu mai puține resurse. Astfel de evoluții sunt cele care permit progresul prin extinderea a ceea ce se poate face din punct de vedere tehnic.
- Sub-Pseudo Labels (Sub-Pseudo etichete) - acest sistem îmbunătățește recunoașterea acțiunilor în videoclipuri, ajutând la o varietate de înțelegeri și sarcini legate de videoclipuri.
Acești algoritmi nu impactează în mod direct clasamentul, dar au impact asupra succesului pe care îl are Google.
Așadar, mai jos prezentăm algoritmii și modelele de bază implicate în clasamentele Google.
RankBrain
Acest algoritm reprezintă punctul de început al introducerii învățării automate în algoritmii Google.
Introdus în 2015, algoritmul RankBrain a fost aplicat interogărilor necunoscute pentru Google (reprezentând 15% dintre acestea). Până în iunie 2016, acesta a fost extins în rândul tuturor interogărilor.
În acest fel, Google a făcut trecerea de la a identifica șiruri de cuvinte, cuvinte cheie sau seturi de cuvine, la a identifica anumite căutări drept entități.
Cu ajutorul acestui algoritm, motorul de căutare poate să vadă dincolo de cuvinte cheie, ajungând în acest fel la adevărata semnificație, exact ca mintea umană. Spre exemplu, dacă se efectuează o căutare de tipul ,,pizza în apropiere de mine”, aceste cuvinte nu vor fi tratate în mod individual, ci vor fi percepute ca o entitate, traduse prin „restaurante care oferă pizza aproape de zona în care locuiesc”.
Pe scurt, RankBrain ajută algoritmii să aplice semnalele lucrurilor în loc să le aplice cuvintelor cheie.
BERT (Bidirectional Encoder Representations from Transformers)
Odată cu introducerea modelului BERT în algoritmii Google, în anul 2019, Google a trecut de la o înțelegere unidirecțională a conceptelor la una bidirecțională.
Un exemplu simplu ar putea fi "mașina este roșie". Abia după implementarea BERT, roșu a fost înțeles corect ca fiind culoarea mașinii, deoarece până atunci cuvântul roșu venea după cuvântul mașină, iar această informație nu era trimisă înapoi.
LaMDA
LaMDA nu a fost încă implementat în mediul natural și a fost anunțat pentru prima dată la Google în mai 2021. Acesta este un model de limbaj conversațional, care pare să aibă un impact simțitor asupra tehnologiei de vârf actuală.
Obiectivul LaMDA este, în principiu, dublu:
1. Îmbunătățirea rezonabilității și specificității în conversație. În esență, LaMDA se asigură că un răspuns într-o conversație este rezonabil și specific. De exemplu, la majoritatea întrebărilor, răspunsul „Nu știu" este rezonabil, dar nu este specific. Pe de altă parte, un răspuns la o întrebare de genul „Ce mai faci?", care este „Îmi place supa de rață într-o zi ploioasă. Seamănă foarte mult cu zborul zmeului." este foarte specific, dar cu greu rezonabil.
LaMDA ajută la rezolvarea ambelor probleme.
2. Atunci când are loc o conversație, rareori este vorba de o conversație liniară. Când ne gândim unde ar putea începe și unde se termină o discuție, chiar dacă a fost vorba despre un singur subiect (de exemplu, „De ce a scăzut traficul săptămâna aceasta?"), în general vom aborda diferite subiecte pe care nu le-am prevăzut la început.
Oricine a folosit un chatbot știe că acestea sunt abisale în aceste scenarii. Nu se adaptează bine și nu transmit bine informațiile din trecut în viitor (și invers).
LaMDA abordează, totodată, și această problemă.
KELM
KELM s-a născut din efortul de a reduce prejudecățile și informațiile toxice în căutare. Deoarece se bazează pe informații de încredere (Wikidata), poate fi utilizat în acest scop. KELM este mai degrabă un set de date decât un model. Practic, este vorba de date de antrenament pentru modelele de învățare automată.
MUM
MUM a fost, de asemenea, anunțat la Google în mai 2021. Deși revoluționar, este extrem de simplu de descris. MUM înseamnă Multitask Unified Model și este multimodal. Acest lucru înseamnă că MUM „înțelege" diferite formate de conținut, cum ar fi teste, imagini, videoclipuri etc. Acest lucru îi conferă puterea de a obține informații în multiple moduri, precum și de a răspunde.
Totodată, MUM poate colecta informații în mai multe limbi și apoi poate oferi un răspuns în limba utilizatorului. Acest lucru deschide ușa către îmbunătățiri vaste în ceea ce privește accesul la informații, în special pentru cei care vorbesc limbi care nu sunt abordate pe internet.
Exemplul folosit de Google este cel al unui turist care dorește să escaladeze Muntele Fuji. Cele mai bune sfaturi și informații pot fi scrise în japoneză și complet indisponibile pentru utilizator, deoarece acesta nu va ști cum să le găsească, chiar dacă le-ar putea traduce.
O notă importantă cu privire la MUM este că modelul nu numai că înțelege conținutul, ci îl și poate produce. Astfel, mai degrabă decât să trimită pasiv un utilizator la un rezultat, acesta poate facilita colectarea de date din mai multe surse și poate furniza el însuși feedback-ul (pagină, voce sau altele).
Unde mai este utilizată învățarea automată?
Am abordat doar câțiva dintre algoritmii cheie care au un impact semnificativ asupra căutării organice. Dar acest lucru este departe de a reprezenta totalitatea domeniilor în care este utilizată învățarea automată.
La întrebările de mai jos, răspunsul este unul singur.
- În marketing digital, ce determină sistemele din spatele strategiilor de licitație automată, automatizarea anunțurilor, identificarea de noi clienți?
- În știri, cum știe sistemul în ce mod să grupeze știrile?
- În cazul imaginilor, cum identifică sistemul anumite obiecte și tipuri de obiecte?
- În e-mail, cum filtrează sistemul spam-ul?
- În domeniul traducerii, cum învață sistemul cuvinte și fraze noi?
- În domeniul video, cum învață sistemul ce videoclipuri să recomande în continuare?
Toate aceste întrebări și alte sute, dacă nu chiar mii, au același răspuns: învățarea automat bazată pe inteligența artificială.
Tipuri de algoritmi și modele de învățare automată
Să trecem acum în revistă cele două niveluri de supraveghere ale algoritmilor și modelelor de învățare automată - învățarea supravegheată și învățarea nesupravegheată. Este important să înțelegem tipul de algoritm pe care îl avem în vedere și unde să îl căutăm.
Învățare supravegheată
Pe scurt, în cazul învățării supravegheate, algoritmul primește date de instruire și de testare complet etichetate. Acest lucru înseamnă că cineva a depus efortul de a eticheta mii (sau milioane) de exemple pentru a antrena un model pe date fiabile. De exemplu, etichetarea cămășilor roșii în x fotografii cu persoane care poartă cămăși roșii.
Învățarea supravegheată este utilă în probleme de clasificare și regresie. Problemele de clasificare sunt destul de simple și se referă la a determina dacă ceva face sau nu parte dintr-un grup.
Un exemplu în acest sens este Google Photos. De asemenea, ReCAPTCHA (Nu sunt robot) se bazează pe același principiu. Utilizatorii ajută în mod regulat la antrenarea modelelor de învățare automată.
Problemele de regresie, pe de altă parte, se referă la probleme în care există un set de intrări care trebuie să fie puse în corespondență cu o valoare de ieșire.
Un exemplu simplu este acela de a ne gândi la un sistem de estimare a prețului de vânzare al unei case, având ca date de intrare metri pătrați, numărul de dormitoare, numărul de băi, distanța față de o locație importantă și altele.
Deși este cu siguranță mai complexă și cuprinde o gamă enormă de algoritmi individuali care îndeplinesc diferite funcții, regresia este probabil unul dintre tipurile de algoritmi care determină funcțiile de bază ale căutării.
Învățare nesupravegheată
În învățarea nesupravegheată, un sistem primește un set de date neetichetate și este lăsat să determine singur ce să facă cu ele.
Niciun obiectiv final nu este specificat. Sistemul poate să grupeze elemente similare, să caute elemente aberante, să găsească corelații etc.
Învățarea nesupravegheată este utilizată atunci când există o mulțime de date și nu se știe dinainte cum ar trebui să fie folosite. Un bun exemplu ar putea fi Google News. Google grupează știri similare și, de asemenea, scoate la suprafață știri care nu au existat anterior.
Aceste sarcini ar fi cel mai bine îndeplinite în principal (dar nu exclusiv) de modele nesupervizate. Modele care au „văzut" cât de reușită sau nereușită a fost gruparea sau suprapunerea anterioară, dar care nu sunt capabile să aplice pe deplin acest lucru la datele actuale, care sunt neetichetate (așa cum au fost știrile anterioare) și să ia decizii.
Este un domeniu incredibil de important al învățării automate în ceea ce privește căutarea, în special pe măsură ce lucrurile se extind.
Google Translate este un alt exemplu bun. Nu ne referim la traducerea unu la unu care exista înainte, în care sistemul era antrenat să înțeleagă că cuvântul x în engleză este egal cu cuvântul y în spaniolă, ci mai degrabă la tehnici noi, care caută modele de utilizare a ambelor limbi, îmbunătățind traducerea prin învățare semi-supervizată (unele date etichetate și multe altele nu) și învățare nesupravegheată, traducând dintr-o limbă într-o limbă complet necunoscută (pentru sistem).
Modele de învățare automată pot fi utilizate pentru a îmbunătăți înțelegerea site-urilor, a conținutului, a traficului și a multor alte aspecte.
Sursa care a stat la baza creării acestui articol: https://searchengineland.com/machine-learning-search-terms-concepts-algorithms-383913
| < Anterior | Următor > |
|---|